All You Need is Loops (and Humans)
I was young and needed the money. I wrote Human-written, certified AI slop™ when I was studying.
Articles about couches. Furniture companies hired students like me to write content that would make their websites rank higher in Google. “Write about advantages, disadvantages. Incorporate these keywords.” The content was shitty because it was never supposed to be read. Just meant to game search algorithms.
Most people blame LLMs for slop.1 But slop existed before LLMs. I’ve written it. LLMs learned this pattern from us: give vague instructions without context, get slop. The problem isn’t the tool.
There’s a divide in engineering right now. Half handcraft their work: they see LLM output as slop. Half optimize for speed2: they use LLMs but sometimes produce slop anyway. Both end up frustrated.
I’ve been on both sides. Now I spend most of my time not coding (1:1s, code review, coaching) yet I still deliver features every week. The difference isn’t the tool. It’s how you use it.
The Human Problem
What is a “one-shot”? A One-shot is how most people use LLMs. You open ChatGPT, type “write me an article about xyz in style abc,” and wait. The LLM produces a draft. You correct: “no, don’t make it marketing style.” The LLM revises. You correct again.
You are now 1.5h in. The LLM had a good first draft, but it starts to fall apart left and right. You removed AI slop, but it wants to smuggle in words like “delve” and wants to replace perfectly fine wording instead. It feels like it’s backstabbing you when you’re not looking.
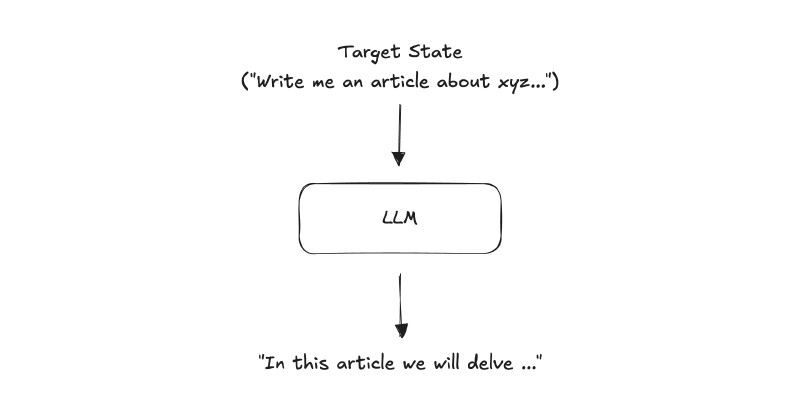
A one-shot prompt gives the LLM a target state (‘Write me an article about xyz…’) and expects a finished result. The output is typically slop: ‘In this article we will delve…’
Most people use LLMs this way, and most LLM output is slop.
LLMs don’t fail. The humans behind them do. An LLM is just a tool, and you don’t blame the drilling machine either when the human is using it to drill a hole into the wrong wall.
One-shot is humans telling the LLM what without teaching it how. It’s like waking an expert in the middle of the night and asking them to solve a problem. They’ll reach for the first thing that sounds right, no time to think it through. The LLM has no tools to explore, no method to follow. It reproduces patterns from its training data, which draws heavily from internet text and is therefore full of slop.
We have a rule here at UMH: “The LLM never writes your code, the human does.” When a PR (pull request, a code change proposal) breaks production, you don’t say “Claude fucked up.” You say “I fucked up.” You opened the PR. You must trust the PR. Not because you typed every character, but because you understood the problem and can defend the result.
This makes LLMs a double-edged sword though. If you understand the problem, they help you think faster. If you don’t understand, they help you produce slop faster.
LLMs are amplifiers. They make you faster at whatever you’re already doing.
How do you avoid this?
The Human in the Loop
The fix is simple: stop giving the LLM a destination. Give it a process.
What is a “loop”? In a loop, “write me an essay on ABC” becomes: “Find three highly cited papers supporting X. Compare their claims. Look for counter-arguments.” For a small article you would have likely never researched in scientific papers, but with the LLM you can.
Instead of a target state, you give the LLM a) a process and b) a vague definition of done.
Give the LLM access to tools, such as Internet Search. The LLM can then follow the process and do multiple iterations until it has found, in our example above, three highly cited papers.
These multiple iterations until a definition of done is reached are what I call a loop. The human creates the loop.
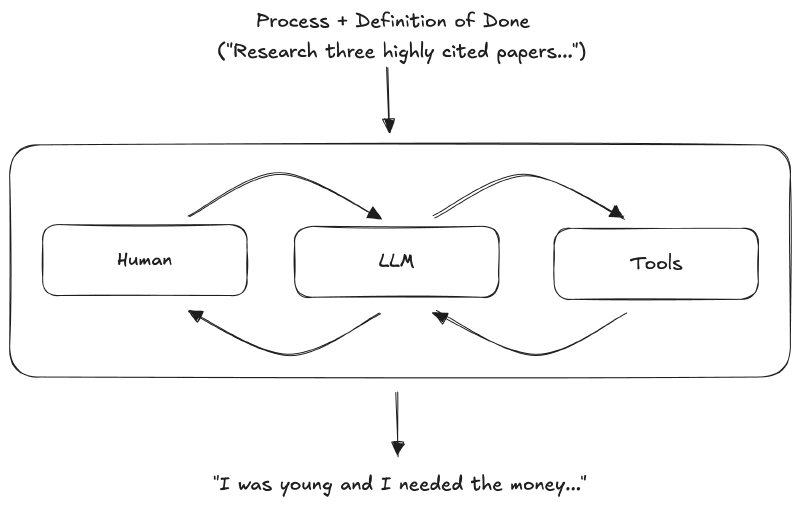
In a loop, you give the LLM a process and definition of done (‘Research three highly cited papers…’). Human, LLM, and Tools iterate together until the human judges the result good enough.
Therefore, the human must always be in the loop.
We had a team discussion at UMH recently: “The LLM writes too many stupid tests.” But what’s a “stupid/unnecessary test”? First we blamed the LLM, because we thought that without it this would never have happened. Then we realized there’s no consistent definition of what a good vs a bad test is. One person came from a company that wrote thousands of unit tests. Someone else suggested ditching unit tests altogether, as they’d done at previous companies, and using integration tests instead. We corrected ourselves: yes, the LLM made the person faster. The disagreement was always there. The speed just made it visible sooner.
That’s why the “bigger/outer loop” must contain a human. We at UMH disagreed on what counts as a useful test. Not because someone was wrong, but because “good” is contested. LLMs can’t resolve human disagreements about value.
You will see this “enforcement of the human in the loop” pattern in most good coding agents implementations.
Claude Code has a “plan mode” where the LLM asks questions before proposing anything: “Which approach should I take? What trade-offs matter here?” It helps the human explore options. Because it can’t decide for the human what counts as good.
How Loops Work
Loops work when you give the LLM a process with a vague definition of done, and NOT a fixed target state.
Two types of loops exist: execution loops (where machines verify “done”) and planning loops (where humans verify “done”). In an execution loop you set constraints and let it run automatically against tests or sub agents (more on this later). In a planning loop you stay in and steer: reading output, noticing gaps, directing.
Execution Loops: When machines verify “done”. For example, in programming with LLMs you can let the LLM work using TDD (Test-Driven Development).
TDD is a traditional programming method where first the tests containing the business logic are written. A test in a banking app could be something like “when the user enters valid credentials, he is redirected to his homepage”.
This works well with LLMs because TDD is often tedious groundwork, necessary but unloved. LLMs handle this with ease. You define what should be tested; the LLM handles the tests and the code. They run in a loop of writing code, testing, and refactoring until the tests pass.3 Combine this with code quality linters or LLM reviewers such as CodeRabbit and you have good working high quality code.
Sometimes the LLM will hallucinate. Or make stupid mistakes that no human would have ever done. Loops will not magically solve hallucinations, but loops will reduce the likelihood of them appearing. Or when they appear, they will be automatically detected and fixed in the next iteration.
To prevent the LLM for example from writing “stupid tests," we at UMH took an existing testing anti-patterns checklist, extended it with our own rules, and fed that to PR reviewers like CodeRabbit.
This also works for non-programmers. You need to give it something it can test against.
Let’s take writing. You could set up a writing loop where the LLM keeps testing against a grammar checker to catch typos. Or against Style guides that flag passive voice.
Or set up a loop that spawns a fresh subagent (a new AI conversation with clean context) dedicated to finding “AI slop” and then another that takes the findings and fixes it.
The coding and non-coding loops run on their own because a machine can verify success. But what about “is this argument convincing?” or “does this structure make sense?”
Planning Loop: When only a human can judge “done”. In a planning loop, you stay in and guide the conversation. The LLM proposes, you evaluate, you redirect. Each approved step becomes a checkpoint. The definition of done is “until I can defend this.”
In a planning loop, completed steps usually stay done. You ask for PRO arguments, get them, approve them, and lock them in. Then you ask for CON arguments, get them, approve, lock them in. Then you work on addressing counter-arguments. Because the previous steps were locked in, the LLM won’t suddenly remove something or modify it without saying anything. This doesn’t mean the human can’t touch the arguments, but they remain locked in until a specific prompt comes to modify them again.
This is why coding agents, such as Claude Code or Codex, perform much better in my experience. The file system is the checkpoint. Every time they want to change something, you must approve. Or you let it fully loose on certain parts of the file system: The agent then edits ten lines, runs tests, finds issues and then continues editing. It will not regenerate your code from scratch.
And coding agents also work well on non-coding tasks. Take brainstorming. “Find three arguments PRO this claim.” LLM researches, returns three. You read them. “Argument 2 is weak. Find a stronger source.” LLM searches again. “Good. Now find counter-arguments.” LLM researches. “The counter to argument 1 is compelling. How would I address it?”
In a loop, approved steps stay done. In a one-shot, you gamble every turn.
Some argue this isn’t “real thinking”—that if you’re not writing sentence by sentence, you’re not generating ideas. I disagree. When I read what the LLM produces and notice “wait, this doesn’t address X,” I’ve generated an insight. The LLM didn’t surface X. I did, by noticing its absence.
Is this weaker than writing from scratch? Maybe. But I’m also reviewing more volume, catching gaps I’d miss in my own writing because I’m too close to it. And I deliver more.
My self-check: Would I defend this output if challenged? If not, I’m producing slop.
Conclusion
Smart people avoid LLMs because LLMs produce slop. Equally smart people (Armin Ronacher, Simon Willison) use LLMs for almost everything. The gap is how they use it.
One-shot fails. Loops work. Give the LLM a process with checkpoints. Keep the human in the loop - not because LLMs are bad at execution, but because “done” is a judgment call.
LLMs are amplifiers. Use them in loops.
But here’s what I can’t resolve.
Most code doesn’t need to be art. It needs to work. Like knives: most people don’t need handcrafted Japanese steel. They need affordable knives that cut. The need for handcrafted code will shrink to where it belongs: infrastructure, security, the parts that need to be art. The rest just needs to cut. (Programmers have heard this before: “C will never match hand-written assembler.” They were right. But in the end, it didn’t matter and C still won.)
To know a good knife, though, you have to learn something about knives first. I learned to code by debugging my own mistakes. I learned to write by writing badly. Can LLMs and loops let you skip the struggle? Or do you need to fail yourself before you can judge what “good” even means?
I don’t know. But until we do, loops still need humans. Not just to decide what’s done, but also to decide what’s good. Someone has to hold the line on value.
Try one loop yourself. See what changes.
Thanks to Niklas, Paul, Diederik, Daniel, Matthew, Leonie, and Brian for feedback on drafts.
Merriam-Webster, “2025 Word of the Year: Slop”, https://www.merriam-webster.com/wordplay/word-of-the-year ↩︎
James Somers, “Speed Matters” (2015), https://jsomers.net/blog/speed-matters ↩︎
Anthropic’s ralph-wiggum plugin automates this exact pattern. ↩︎