The Unified Namespace as the Strongest Architectural Proposal for Industry 4.0
· Originally published on learn.umh.app
You are skeptical. You are skeptical of buzzwords. You are skeptical because in the past 10 years of Industry 4.0, nothing really changed. And now there are random people on the internet talking about this “Unified Namespace” or in short “UNS”. Of course, you are skeptical.
But you are also open to new concepts; otherwise, you would have never clicked on this article.
Let’s take this openness and use it to explain, in my personal opinion, one of the strongest architectural proposals for IT/OT convergence. I don’t want to sell you a dream but to equip you with the facts and the background necessary to understand the hype of the “Unified Namespace.” Its biggest advantage is that it has strong roots in the traditional frameworks of IT and OT systems architecture.
This article stitches together what was originally published as a 4-chapter course on learn.umh.app. It walks through the Unified Namespace from three angles: how it slots into existing OT systems (Chapter 1), where the term came from and what it actually means (Chapter 2), how it grounds in established IT principles (Chapter 3), and concrete examples from the field (Chapter 4).
Chapter 1: The Foundations of the Unified Namespace in Operational Technology
The Unified Namespace arises from the need to address limitations in standard Operational Technology (OT) practices. Let’s start with the basics of OT and the automation pyramid’s role in it.
The Automation Pyramid
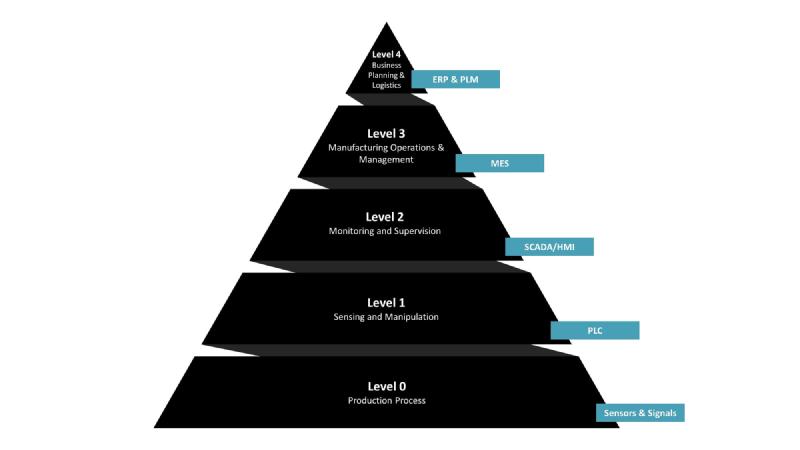
The Hierarchical Structure of Industrial Control Systems: The Automation Pyramid
For IT and management professionals, the Automation Pyramid is a key concept. It’s a structured representation of how data in a manufacturing setting moves from the production floor to strategic decision-making levels. The pyramid aligns with the ISA-95 standard, offering a framework for understanding factory control systems. It’s a bridge between IT and OT: the higher you go, the more you lean towards IT with aggregated data; the lower, the closer you are to OT and the hardware.
Challenges of the Automation Pyramid
Unfortunately, the traditional Automation Pyramid faces significant challenges in today’s data-driven industrial environment. These challenges are not just some small technical hurdles; they are actual very expensive barriers to innovation. Why do manufacturing companies find it hard to have a simple dashboard with analytics, like a list of all orders and a live progress bar for each order’s production? A big reason is the automation pyramid, despite its benefits:
Data Aggregation and Loss: In the traditional pyramid, as data moves up from the PLC level, it undergoes aggregation, which might seem efficient but comes at a significant cost: the loss of detailed information. For instance, in vibration monitoring, the raw data essential for machine learning models is lost in aggregation. Similarly, in filling industries, the exact timestamps of produced items are replaced by simplified batch summaries. This data simplification, while useful for basic reporting, strips away the granular details for continuously improving the production such as identifying bottlenecks or understanding production patterns.
Firewall Barriers: Multiple firewalls protect the shop floor, creating a fortress around the data. While this is important for security, it turns accessing data into an odyssey, especially for data scientists. To access data at the PLC level, one often needs to be physically present at the machine, or navigate through multiple VPN tunnels and jump hosts across different organizational segments. This time-consuming and non-automatable process severely restricts the use of data for advanced analytics and real-time decision-making.

Data Scientist accessing old OT systems (obligatory xkcd #2221)
Integration Hurdles: Imagine the challenge of creating a unified dashboard that displays real-time production data alongside ERP/MES information. For example, a dashboard that shows all upcoming and completed orders from the ERP/MES system, and the current progress of each (both in terms of quantity produced and pending production). In the traditional pyramid, this requires a complex, multi-step data flow across various levels – from PLC for current production stats to ERP/MES for order lists – each layer separated by its own firewall. This setup not only makes it expensive and time-consuming to implement new applications or dashboards but also leads to rigid structures. Once set up for a specific purpose, any minor change can disrupt the entire system, often leading to a reluctant acceptance of suboptimal setups.
Transmission Inefficiencies: Higher levels of the pyramid, like ERP and MES systems, are designed for transactional data processing (OLTP), not for handling large volumes of analytics data (OLAP). This design limitation means that even if we manage to transmit data from lower levels, these systems might not support or efficiently handle it. Because of this, companies frequently create specialized data flow processes tailored for specific situations. For instance, they might transmit a progress indicator in percentage (0%-100%) rather than the actual number of pieces produced per second. Any shift in requirements can make the entire system outdated (e.g., adding a rate of progress display), leading to additional costs or, worse, a reluctance to implement necessary changes.
Go to chapter 3 if you want to learn more about OLTP and OLAP databases.
Does this mean we should discard our existing systems? Absolutely not! Instead, we can significantly improve our already existing setup by adding the Unified Namespace.
Chapter 2: The Rise of the Unified Namespace
At the heart of this emerging concept stands Walker Reynolds, an educator/influencer who offers a unique OT/system-level perspective on the Unified Namespace (UNS).
Definition of the UNS
Walker describes the Unified Namespace (in short: UNS) as a framework where all applications and devices in Industrial IoT act as interconnected nodes, sharing and accessing data in a single unified location.
To be honest, that is quite a vague definition. So let’s clear it up! There are additional key components that people typically talk about when talking about Unified Namespace:
Component 1: Event-Driven Architecture
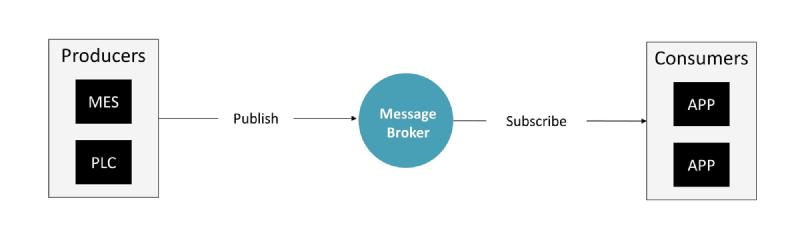
Standard Image of an Event-Driven Architecture, Publish/Subscribe pattern, and similar
The foundation of a UNS is an Event-Driven Architecture, which facilitates real-time message exchange between multiple entities, referred to as consumers and producers. Central to this architecture is the use of a message broker. In the UNS, almost always people talk about MQTT as the central message broker protocol. There are some commercial vendors out there, which we compared here. In Chapter 3 of this article, we will go through the origins of UNS and go a little bit more into detail of alternatives to Event Driven Architecture here.
Component 2: Standardized Topic Hierarchy
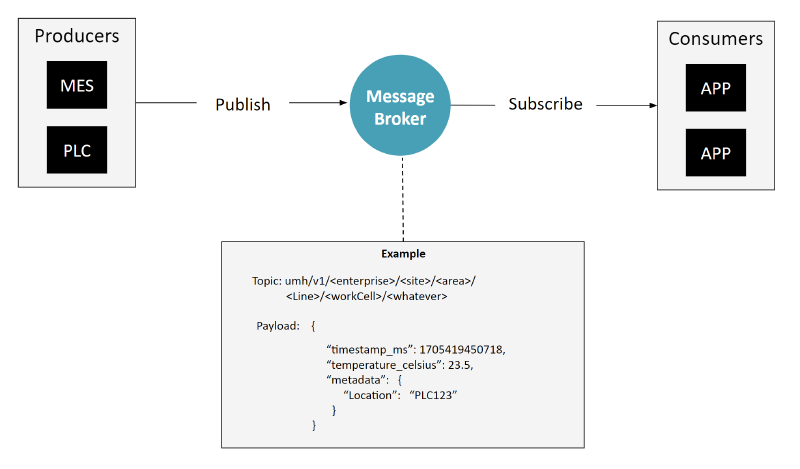
Event-Driven Architecture with a standardized topic and message payload. So far, nothing really new except that the topic hierarchy is typically done based on some form of ISA95 hierarchy.
Additionally, the system employs a standardized topic hierarchy accompanied by a defined message schema. This typically follows an ISA95-style framework for topic organization (encompassing enterprise, site, area, line, and cell levels). While this hierarchy is generally consistent, adaptations are common across different industries - for instance, energy companies might use the KKS System, and pharmaceuticals often adopt ISA88 principles. Furthermore, assets might be classified numerically, and lines and cells can be merged, among other variations. The message schema becomes important when scaling, as it ensures adherence to the topic hierarchy and standardizes the messages within it.
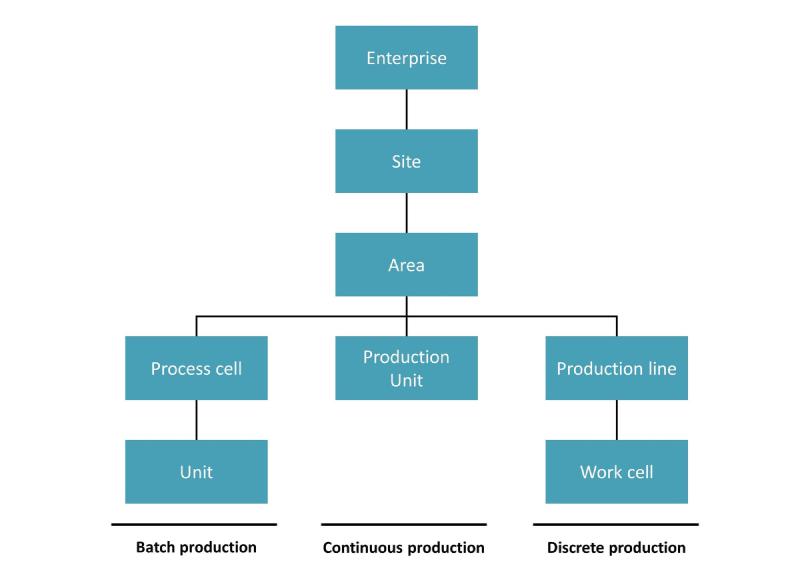
ISA95 / IEC 62264 shopfloor architecture that is typically used as the base for most topic hierarchies
Take a look into the final words chapter for more information on designing the topic hierarchy.
Component 3: Messages are sent to the message broker regardless of the immediate presence of a consumer.
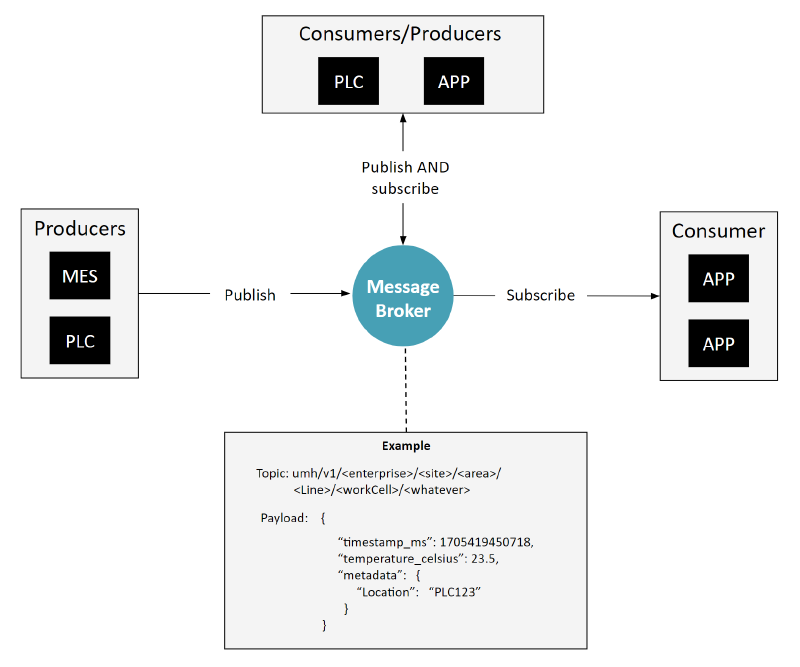
Sending messages to the broker independent on whether the data is needed or not, has an interesting conclusion: there should be no pure subscribers, as every subscriber should also send back at least some of the data it processed.
This strategy diverges from conventional IT practices, where the production of data for a message broker or an event-driven architecture usually hinges on the existence of a consumer.
Our initial thoughts, formulated before the concept of the Unified Namespace gained widespread recognition, centers on the fact that establishing connections and extracting data on the shop floor is a time-consuming process. Therefore, our initial step involves sending all accessible data during the configuration of the producer or the protocol converter into the message broker. Once this data reaches the message broker, we can more easily determine which data points to retain, whether down sampling is necessary, and so forth. It’s likely that many professionals working with Unified Namespace employ a similar approach, often instinctively, without much discussion.
This method is feasible because the volume of data from OT systems is generally minimal compared to the capacity of contemporary IT applications. Consequently, these applications are typically indifferent to whether they receive a few hundred data points per second or as many as 30,000.
Part of this approach also entails that any application which extracts data must also contribute its processed data back into the system. This results in significant time-saving when expanding existing use-cases. Because all the data is already there, available in a simple, standardized and easy to access format, adding a couple of data points to the dashboard, or setting up an AI model, becomes a thing of a couple hours.
Some refer to this as “democratizing data”, which you might know when you work at a larger enterprise and struggle to sometimes get very few data points.
Component 4: Stream Processing / Data Contextualization
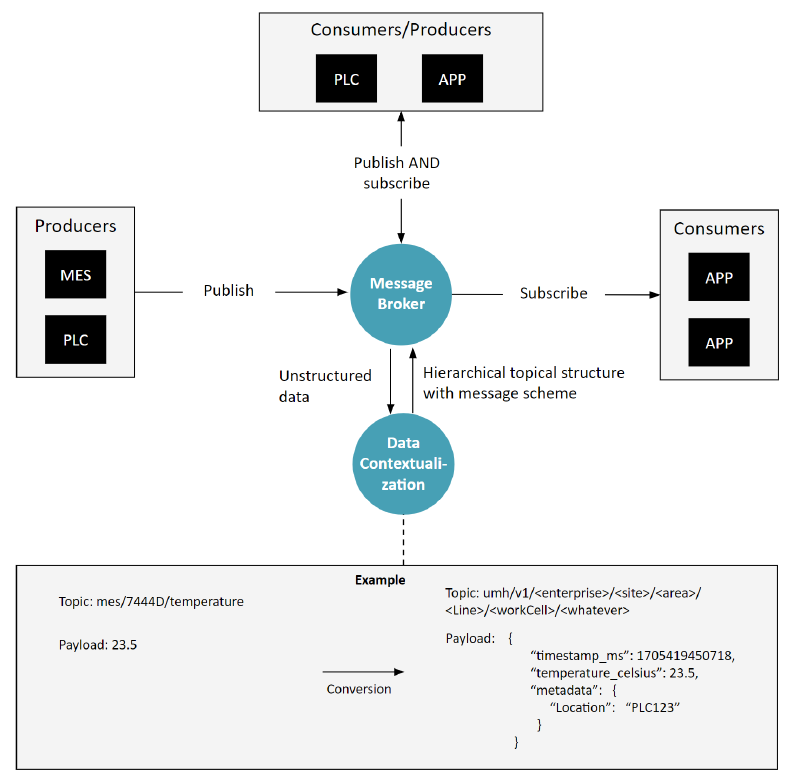
Adding a new technology component \data contextualization\, \stream processing\ or \IIoT platform\ to standardize and structure data within the Unified Namespace
So far, our discussion on technology has been centered mainly around a message broker and certain rules (like topic hierarchy, schema, and what to publish). However, there is another key technological component essential to a Unified Namespace, which we refer to as Stream Processing or Data Contextualization. These steps can be done either in smaller tools or inside of an larger IIoT platform.
The core function of this component is to properly place data into the Unified Namespace. This means ensuring data fits into the correct topic hierarchy and conforms to established message schemas.
For example, consider a message 23.5 coming in on a topic mes/7444D/temperature. One could now assume that it is a temperature in celsius coming from the MES from a device called 7444D. This component might take this raw data, identify it as a temperature reading, and then place it under a specific topic like umh.v1.united-manufacturing-hub.cologne.weather together with a more standardized payload containing a timestamp and metadata within the Unified Namespace.
Tasks can range from this simple, like redirecting a message to a different topic, to more complex, such as breaking down a large message into multiple smaller events across various topics. Additionally, it can involve sophisticated algorithms for data processing. For instance, it might implement a rule that triggers an action if a machine’s vibration exceeds 30, indicating potential issues in operation.
Common tools used in this process include Node-RED, Ignition, and HighByte.
Component 5: Protocol Converters
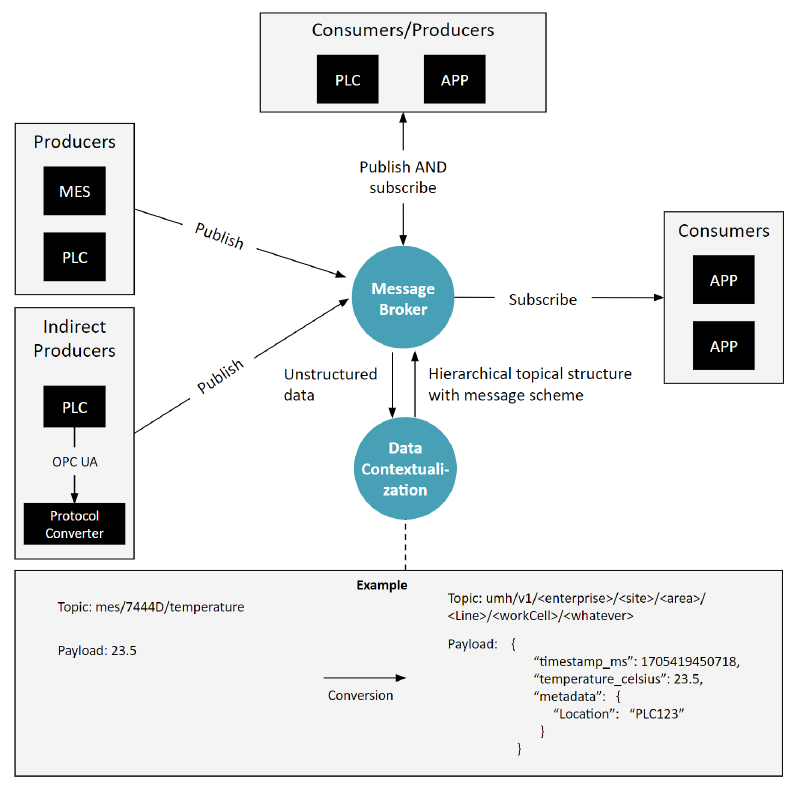
Our final diagram includes the option for protocol converts, if a producer or consumer does not speak the message brokers protocol.
Optionally, there are also “protocol converters” in cases necessary, where the consumers might not speak MQTT, but OPC UA or SQL or something else, so the data first needs to be converted from these protocols into the event-based messages.
This sounds easy at first, but the reality is way more complex. Especially, when the origin of the data is not something event-based, but instead something like a database. In the chapter “final words” you will find more reading material on this topic.
The result: Open and Replaceable Architecture
The Unified Namespace as a framework with various interconnected nodes
Firstly, it represents a truly open architecture. The term “open architecture” has often been misused by many large-scale OT vendors, who have branded their proprietary, restrictive architectures (or protocols, like OPC UA) as “open.” This is misleading because if we define “open” as “allowing every application or person easy access to data,” it implies that the underlying interfaces should be simple, well-documented, non-proprietary, and supported by multiple major vendors from various ecosystems. While OPC UA is extensively documented, it is far from simple. A system that needs hundreds of lines of code just for data extraction is not user-friendly. It’s essentially limited to large vendors who can afford to invest in heavy SDKs.
Moreover, the Unified Namespace is a vendor-independent, replaceable architecture. This aspect challenges established market vendors as it enables the replacement of any software component with minimal vendor lock-in, in line with UNS guidelines. Even key components like the message broker are interchangeable, as seen in the variety of available MQTT brokers. For instance, a salesperson promising exceptional results can be granted access to the company’s data through the UNS to demonstrate the value of their application within hours. Similarly, if a vendor fails to meet expectations, they can be readily replaced with another. This flexibility and independence from single vendors is a key feature of this architecture.
To illustrate these concepts more clearly, let’s use an easy-to-understand metaphor.
The Unified Namespace as a 1980s News Agency
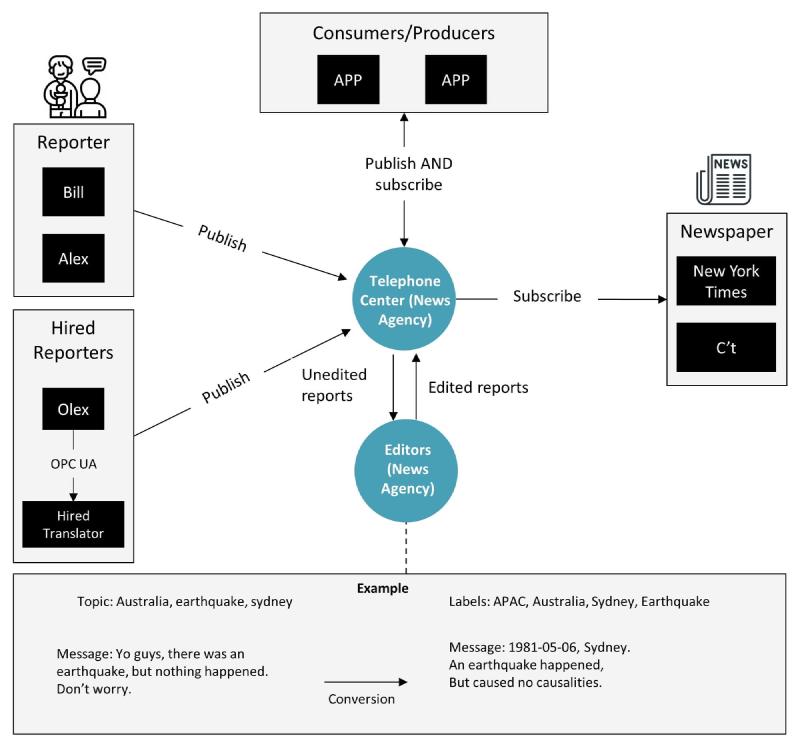
We can replace almost every aspect of the Unified Namespace with a person from a 1980s News Agency.
Imagine the Unified Namespace as a bustling news agency from the 1980s. In this agency:
- Reporter and Messages (Data Producers and Events): Each data source in the Industrial IoT is like a reporter. Just as a reporter sends news about events to the news agency, like an earthquake in Sydney, these data sources generate messages about events in the factory and sends them to the message broker. They label these messages with specific tags, such as “earthquake”, “Australia”, “Sydney”, mirroring how data is tagged with a topic hierarchy in the UNS.
- Telephone Center (Message Broker): The news agency’s telephone center, where all messages first arrive from the reporters, is akin to the MQTT message broker in the UNS. It’s the central hub where all information is initially collected before being processed.
- Sorting and Organizing (Stream Processing): The agency staff who sort and organize these messages, adding missing labels or editing for clarity, represent the stream processing component in the UNS. They ensure that each piece of information is correctly categorized and formatted, much like organizing data into the right topic hierarchy and message schema. Once they have all the proper labels, they go back to the telephone center, where the distribution then starts.
- Distribution to Newspapers (Data Consumers): Different newspapers have different interests, similar to how various applications in the UNS subscribe to specific topics. The New York Times, interested in a broad range of topics, might receive information on the Sydney earthquake, while a specialized IT magazine might only receive tech-related news. The New York Times would have probably subscribed to everything in APAC and below, similar to using a wildcard subscription in a message broker such as
world/apac/#. The IT magazine would have probably subscribed to something likeinformation-technology/#. This reflects how data consumers in the UNS selectively access the data they need. In the telephone center of the news agency, they would for each message look at the labels, and then inform the subscribers of these labels about the related information. - Protocol Converters (Translators): In cases where local reporters don’t speak English or information is in a different format, translators are used. These are like the protocol converters in the UNS, translating different data protocols into a unified event-driven format for ease of integration.
- Open and Flexible Structure: Just like a news agency can quickly adapt to new types of news or local changes in reporting standards, the UNS’s open architecture allows for easy integration of new data sources, tools, or technologies without vendor lock-in. This flexibility and openness make it a powerful framework for modern industrial applications. Just to be clear: it is perfectly fine to use vendor-specific software in the UNS, as long as it’s a producer or consumer, and not baked into the actual UNS architecture.
Where is the Data Stored in the Unified Namespace?
A common question about the Unified Namespace (UNS) is about data storage. Typically, we observe that the UNS primarily functions as an event-driven architecture (refer to the above definition), but for data storage, additional components like a Historian or an open-source database are added (see also the architecture of the data infrastructure of the UMH). While the UNS does feature message buffering, holding data temporarily until it’s received by all consumers, this method is not suitable for storing data over extended periods, such as several years. Message brokers, which are central to the UNS, are not designed for long-term data storage.
To learn about how we at UMH approach the topics of “Visualizing” and “Browsing” the UNS, check out the last chapter. Here’s a little spoiler: we add our Management Companion (akin to an agent) to each message broker. This companion continuously monitors the broker, extracts information, and compiles it into a single ISA-95 style tree structure in the Management Console.
The Rise of Unified Namespace on the Internet
Despite some ambiguity in its definition, the Unified Namespace has attracted a significant following. Its growing popularity is marked by the increasing number of members in Walker Reynolds’ Discord community (over 5,000 as of September 15, 2023) and mentions in authoritative industry reports, including those by Gartner.
The Unified Namespace (UNS) is seen as a solution to the limitations of the traditional ISA95 Automation Pyramid. It acts as a central hub, gathering real-time data from every layer of the automation pyramid and organizing it in a structured, accessible format. This system uses a message broker at its core, ensuring all data is available in real-time and in a usable form.
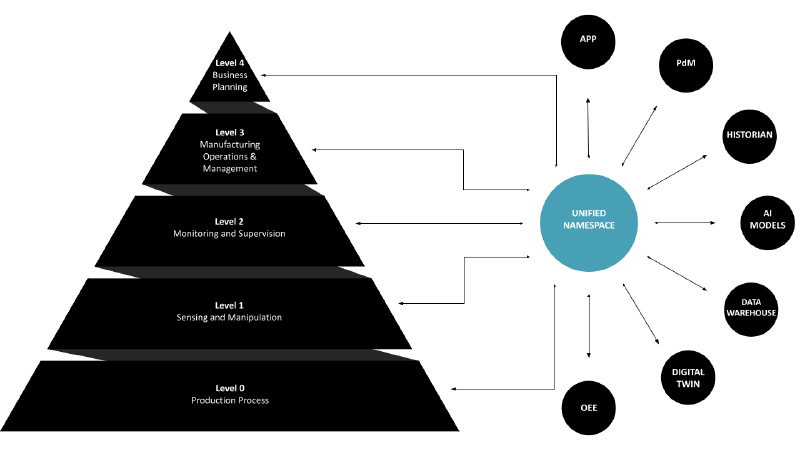
The Unified Namespace can be used to extend the traditional Automation Pyramid
Now to its practical applications. By sourcing data directly from each layer of the pyramid, UNS facilitates access to high-quality, raw data. This unified data environment greatly simplifies the development of cross-layer applications. For example, a dashboard could simultaneously show MES order information and real-time machine updates such as live temperature and pressure readings, providing invaluable insights to operational staff.
The financial benefits are equally compelling. Integrating new applications with UNS is not only more cost-effective but also less risky. The ease of access to data means new applications can be prototyped quickly and without substantial initial investments. Check out the LinkedIn article from our colleague Denis for some concrete examples.
This is particularly beneficial in regulated industries, like pharmaceuticals, where the introduction of new applications does not necessarily mandate a complete re-qualification of processes, as the foundational structure of the pyramid is maintained.
The deployment of UNS is generally a phased process. It starts with setting up a message broker and connecting a few initial data sources. Once the system’s efficiency and effectiveness are established, it can be expanded to include additional data sources, typically driven by the specific requirements of individual use cases.
Understandably, there’s some hesitancy and a need for clarity, especially when it comes to gaining trust and explaining this concept to management. The question arises, ‘How can I present this idea effectively? Surely, I can’t just refer them to a YouTube video from an American YouTuber, right?’ This concern is quite common.
I’m not here to falsely claim that the Unified Namespace is widely adopted in its explicit form – that wouldn’t be truthful. It is growing in popularity, but in in the bigger picture it is not widely adopted yet.
Similarly, the so-called ‘Industrial IoT’ platforms and other managed cloud services haven’t seen extensive adoption either. Often, when inquiring about real-world deployments of Industrial IoT platforms, you’re initially met with marketing gloss and impressive sales presentations. Yet, in my experience, a conversation with the actual shop floor personnel in these ‘deployed’ environments reveals a different story. They might not have even heard of the solution, or if they have, it’s likely been used sparingly, maybe a few times months ago.
But let’s not stray too far off course. Instead of relying on fancy slides, I offer something more substantial: the concept of the Unified Namespace is grounded in core IT principles. In fact, major IT companies like Google, Facebook, and Amazon are already utilizing similar concepts at scale. It’s highly probable that your own organization is employing this approach too, albeit under different names.
Chapter 3: The Foundations of the Unified Namespace in Information Technology
It does not matter how you spin it, you will always land up with a Unified Namespace.
It does not matter how you spin it, you will always land up with a Unified Namespace. In various industries beyond manufacturing, it’s known by several names:
- Publish-Subscribe, often abbreviated as Pub-Sub
- Event-driven Architecture
- Event-Streaming
- Message Broker
- Protocols like MQTT, AMQP, Kafka, and more
It is almost everywhere where large amounts of data needs to be processed from large amounts of producers/consumers. In this chapter, I’ll cover two specific perspectives:
- “Unified Namespace” is one fundamental principle on how to build larger applications. This perspective was previously discussed in our article “Comparing MQTT Brokers for the Industrial IoT”.
- “Unified Namespace” is done whenever companies connect to the cloud. This perspective was previously discussed in our article “Integrating the Unified Namespace into Your Enterprise Architecture: An Architect’s Guide.”
“Unified Namespace” is one fundamental principle on how to build larger applications
I’ve touched upon this topic before, but it found an unusual spot at the start of an article comparing MQTT brokers. Let’s revisit it briefly:
In “Designing Data-Intensive Applications”, Martin Kleppmann, a researcher at the University of Cambridge with a remarkable background in companies like LinkedIn, explores the foundational elements of data-intensive applications. The book has garnered high praise from notable industry experts such as the CTO of Microsoft, Principal Engineers at Amazon Web Services or Jay Kreps, the creator of Apache Kafka and CEO of Confluent.
Kleppmann identifies four essential building blocks that form the core of data-intensive applications:
- Long-lived databases to store data
- Short-lived caches to speed up expensive operations
- Stream processing blocks to continuously process and share data
- Batch processing blocks to periodically process batches of data
To connect these building blocks, there are three common architecture approaches:
- Dataflow through databases
- Dataflow through service calls
- Dataflow through asynchronous message passing
Dataflow through Databases
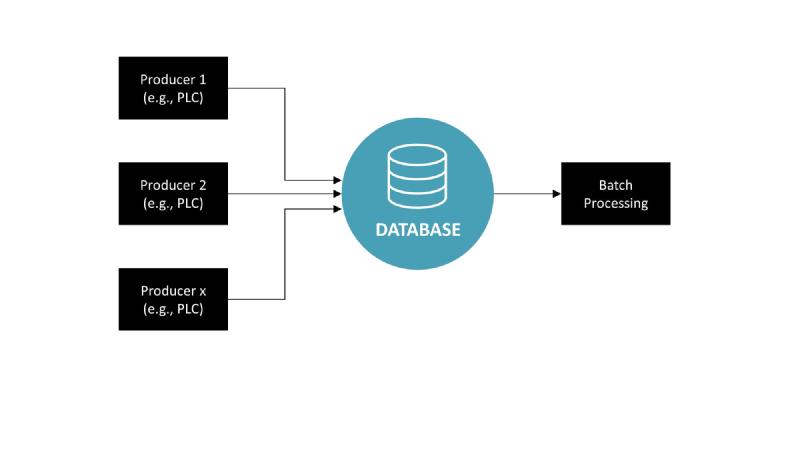
Option 1: Dataflow through databases. No real-time stream processing possible. The database could be something like a Historian.
In this architectural approach, various components that produce data, commonly referred to as Producers (like PLCs, MES, or ERP systems), transmit data directly into a centralized database. This method is straightforward and orderly, with each producer sending its data to a single collection point for storage. From this database, the information can then be used for batch processing, which handles large volumes of data in scheduled operations. However, this setup doesn’t support real-time stream processing, the ability to analyze and act upon data as it’s generated. This is because traditional databases are designed for storage and retrieval, not for the dynamic, ongoing analysis that streaming requires. Therefore, while this model is efficient for historical data analysis and reporting, it lacks the capacity for immediate, continuous insights that modern data-driven operations often need.
Dataflow through Service Calls
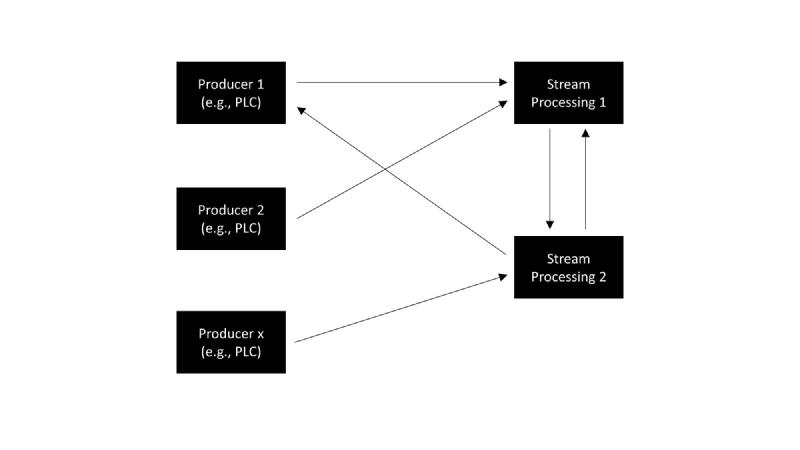
Option 2: Dataflow through service calls. Can cause spaghetti diagrams when scaled up and not properly documented.
In this architecture, data producers such as PLCs are directly linked to various stream processing services. Each producer might send data to multiple services, and each service may receive data from multiple producers, creating a network of connections. This direct interaction enables real-time processing of data streams, as each service processes the incoming data as it arrives.
However, as the system scales and more producers and stream processors are added, the complexity of connections can grow exponentially. This expansion can result in a tangled web of interactions, commonly known as spaghetti diagrams. Such complexity makes the system difficult to maintain, understand, and modify, as every service is interconnected with many others in a non-linear fashion. Without careful design and documentation, this can lead to a fragile system architecture that is hard to debug and adapt to changes.
Dataflow through asynchronous message passing
The third approach, “asynchronous message passing”, introduces a fifth building block: the message broker. This is also sometimes called as “Pub/Sub” or “Event-driven Architecture”.
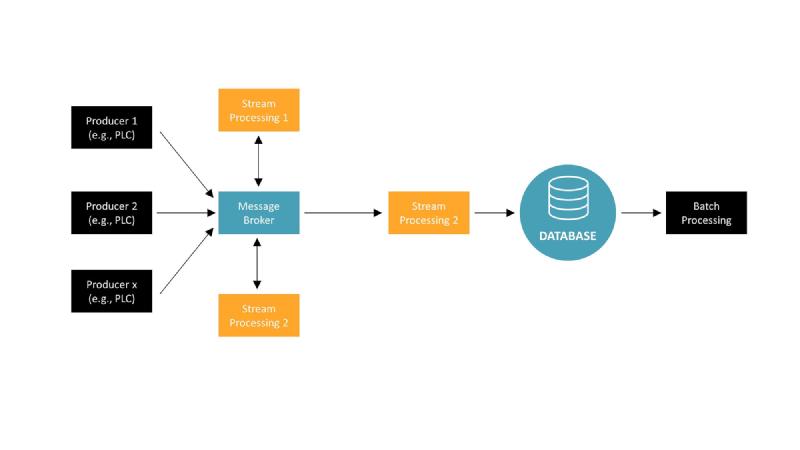
Option 3: Dataflow through asynchronous message passing. Introduces the message broker like Apache Kafka or HiveMQ or RabbitMQ
This architectural model introduces a message broker as the central hub for data communication, which greatly simplifies the data flow between producers and consumers. In the diagram, we see multiple data producers, such as PLCs, sending their data to a message broker. The message broker then distributes this data to various stream processing units based on subscription topics.
Each stream processing unit handles its specific data processing tasks in real time. For example, Stream Processing 1 might handle real-time analytics, while Stream Processing 2 could deal with real-time monitoring. The processed data from these streams can then be funneled into a database for persistence. Additionally, there’s a batch processing unit shown, which could be used for heavier, less time-sensitive computations that can be run on a schedule.
This setup allows for a cleaner separation of concerns and easier scalability. As new producers or consumers are added, they can simply connect to the message broker without affecting the existing system structure. This avoids the intricate and hard-to-maintain web of connections that characterize the “spaghetti diagrams” seen in direct service call architectures. Moreover, the message broker facilitates a more efficient data flow management, ensuring that data is processed in a timely manner and only sent to the parts of the system that require it.
In manufacturing applications, which often run for 10-20 years, it is important to have the ability to easily plug in new components or remove existing ones. This helps prevent spaghetti diagrams and allows for real-time data processing. While introducing an additional building block like the message broker into the architecture might seem like a disadvantage due to its complexity, in the manufacturing sector, the benefits far outweigh these concerns. The ability to process data in real time and adapt to evolving technological needs makes this approach particularly valuable.
Does that not sound familiar? Yes, it is very similar to the concept of a Unified Namespace.
But we can go further:
“Unified Namespace” is done whenever companies connect to the cloud
In a previous article I already discussed this as well. The UNS is really an application of a battle-tested IT-architecture that already enjoys widespread adoption in sectors that are more advanced in IT than the manufacturing industry (banking, startups, etc.). Let’s take another, more summarized, look at this explanation:
Working with data is not something new to manufacturing and that requires new tools and techniques, it is well known in various other fields such as banking, retail, or online platforms (think of LinkedIn, Amazon, etc.). So let’s look at the old, established, tried-and-tested technology because it guarantees stability. No need for fancy stuff.
Let’s start by distinguishing between two types of databases: OLTP and OLAP. OLTP databases are like the diligent record-keepers of daily transactions, ensuring that data is always current for frontline workers. OLAP databases, however, are used by business analysts to dig deep into data history and extract strategic insights.
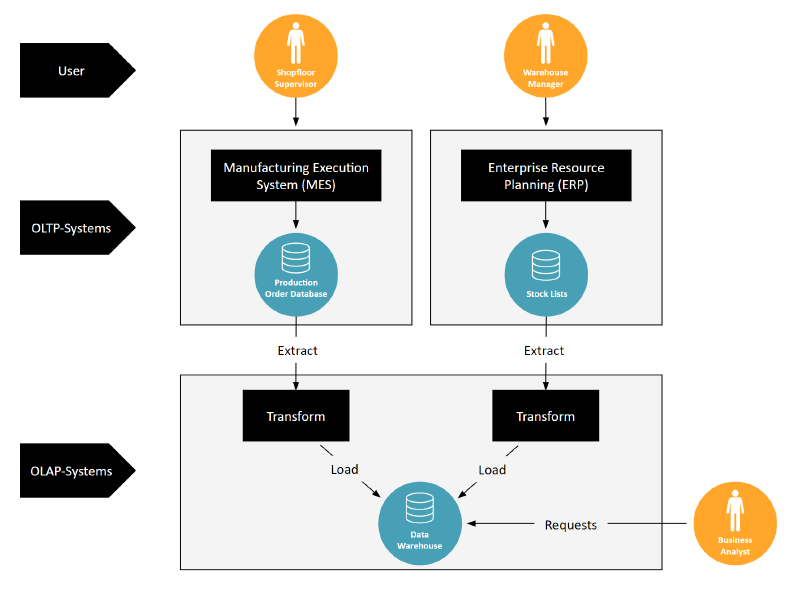
ETL processes connect OLTP and OLAP databases
The connection between OLTP and OLAP systems traditionally happens through an ETL process. This is where data is extracted from OLTP databases, transformed for analysis, and then loaded into OLAP systems. Think of the image with the Manufacturing Execution System (MES) and the Enterprise Resource Planning (ERP) system: data flows from production orders and stock lists into the ETL process, ultimately landing in a Data Warehouse for business analysts to use.
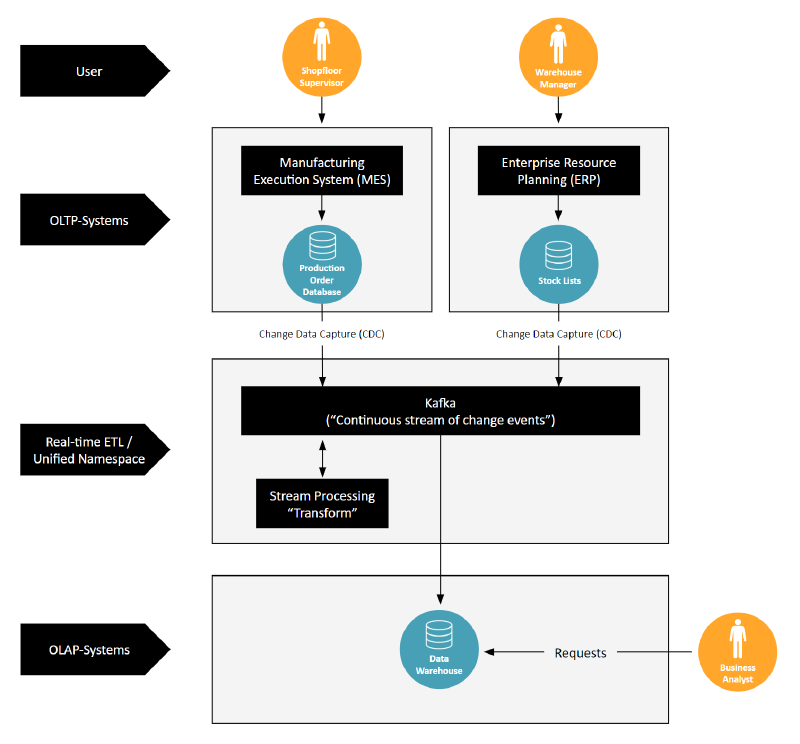
To connect OLTP and OLAP databases real-time ETL such as Apache Kafka can be used
In the modern data landscape, however, there’s a push for real-time data processing. That’s where the second image with Kafka comes into play. Kafka enables a shift from batch processing to streaming data in real time. Using Change Data Capture (CDC), it captures changes as they occur in OLTP systems. This data is then instantly transformed and loaded into OLAP systems, allowing for immediate analytical access.
This process mirrors the Unified Namespace, a ‘continuous stream of change information.’ By adopting Kafka and streaming data in real time, companies effectively create a UNS when they connect to the Data Warehouse (typically also just called “cloud”). This means that all data, as it is generated, is immediately available across the enterprise, breaking down barriers and enabling a unified, agile approach to data management.
As we conclude this exploration, it becomes evident that regardless of the terminology, be it Pub-Sub, Event-driven Architecture, Event-Streaming, or Message Broker, the core concept of a Unified Namespace is universally recognized as a vital component in the architecture of data-intensive applications. This principle holds true across various industries, not limited to manufacturing.
Chapter 4: Examples and Final Words
You might still be skeptical, and I know that. That was a large amount of information, pressed into a small article. Our goal was not to oversell a dream, but to provide you with a clear, factual understanding of why I believe the Unified Namespace is a game-changer in IT/OT convergence.
To further get a better a proper grasp at the concept of Unified Namespace, there are a couple of steps that you can take:
(Video available on the original article on learn.umh.app.)
- Go practical (recommended). Nothing beats trying it out on your own, either with simulated data, or directly with real data from your production.
The quickest way to get some hands-on practice is by leveraging the United Manufacturing Hub. I personally believe that it is one of the best ways, but because I am the CTO of the company behind it, I might not be entirely neutral here. A more neutral alternative can be found further below.
You could start by creating a free account on our Management Console, enable demo mode in your account settings, and explore it (see also video above). If you have a VM or some hardware lying around, you could even install the United Manufacturing Hub and either work with the simulated PLCs that are included with it, or you can directly connect your actual factory setup and utilize the tools you either already have or that are included in the UMH.
By the way: You can use the UMH for free, and only need to pay for compliance features (e.g., SSO, support, guaranteed lifecycle, etc.)
The alternative would be setting up the MQTT message broker mosquitto into your Docker or Linux environment together with Node-RED and MQTT Explorer. It will take more time and it will be not the best user journey, but I also want to show that it is not dependent on any single vendor in the space (including us).
- Stay theoretical. We know that in larger enterprises doing something practically can be time-consuming. If you want to prepare yourself in talking with your manager, colleagues, or just simply want to throw in the concept of Unified Namespace into your internal discussions, you can use the following learning materials:
- You could look at the Architecture and see how we setup the United Manufacturing Hub and how and why we built it the way it is built
- Take a look at our other blog articles, and see if something piques your mind. We regularly write about different topics in the field.
- Contact us, whenever you are ready :) We are happy to answer your questions in our Discord Channel or on LinkedIn. To engage commercially, take a look at our website: www.umh.app
Stay tuned for our next article about data modeling in UNS-based architectures. My current thoughts are a bit unorganized, but you can preview them here: Data Archetypes in Manufacturing.
Appendix 1: Acknowledgements
A special thank you goes out to the people that provided me with feedback during the article creation:
- Jon Forbord
- Denis Gontcharov
- Daniel Helmersson
- Ricardo Maestas
- Some people that want to remain anonymously
And of course our customers and community members!